오늘은 유방암을 구별하는 머신러닝 마지막 실습입니다!
실습 1과 실습 2에서 데이터 분류와 학습까지 완료한 상태입니다.
이제 성능을 높이는 작업을 할게요!

성능을 높이는 작업 두 가지를 하겠습니다.
1. Data Normalization
2. SVM Parameters Optimization
1. Data Normalization
Data Normalization을 하는 이유는 뭘까요?
우리가 pandas dataframe으로 만들었던 데이터의 일부를 가져오겠습니다.
저 데이터들의 값을 하나씩 봐보면 뭔가 불편한 점이 있지 않나요?..
바로!

각각의 feature의 data 범위가 다르다는 겁니다.
예를 들어 mean concavity는 0.xx 범위를 가지고 있는데,
worst perimeter는 100.xx의 범위를 가지고 있습니다.
이 상태로 학습을 시키면 worst perimeter가 학습에 더 많은 영향을 주게 됩니다.
(요즘 머신러닝 도구들은 저절로 이를 조절해 주기도 합니다.)
그래서 이 값들을 0~1 사이의 값으로 모두 맞춰주도록 하겠습니다.
표준화 식은 여러가지가 있습니다.
그중 하나를 쓰겠습니다.
저 식을 쓰면 모든 데이터 값이 0~1 사이의 값으로 나타납니다.
min_train = X_train.min()
range_train = (X_train - min_train).max()
x_train_scaled = (X_train- min_train)/range_train
sns.scatterplot(x = x_train_scaled['mean area'], y = x_train_scaled['mean smoothness'], hue = y_train)
min_test = X_test.min()
range_test = (X_test - min_test).max()
x_test_scaled = (X_test- min_test)/range_testmin_train에는 Xmin을 넣고 range_train에는 (Xmax - Xmin)을 넣어줬습니다.
최종적으로 X_train_scaled을 위의 표준화 식으로 나타냈습니다.
scale이 다른 두 특징 mean smoothness와 mean area가 0-1로 같은 범위를 가지고 있음을 확인할 수 있습니다.
우리가 X_train 데이터를 Normalization해줬기 때문에
X_test도 이와 같은 방법으로 표준화 해주면 됩니다.
2. SVM Parameters Optimization
다음은 우리가 사용한 머신러닝 기법인 Support Vector Machine의 parameter를 바꿔주는 방법이 있습니다.
우리가 볼 parameter는 두개 입니다.
- C parameters : penalty를 적게 주느냐 많이 주느냐를 결정하는 변수(과적합을 조심해야 함)
- Gamma parameters : 감마 값이 크면 support vector machine의 초평면에 가까운 지점에만 집중을 한다.(과적합 조심)
- C parameters가 커지면 틀렸을 때 penalty를 많이 주게 됩니다.
즉 값이 커질수록 정확하게 예측합니다.
- Gamma parameters도 똑같이 생각해주면 됩니다. 값이 크면 결정경계 주위에서 판단을 하기 때문에
정확도는 올라갑니다.
하지만 정확하게 예측할수록 좋은 것일까요?

우리가 준 데이터에 대해서 정확하게 예측하겠지만,
우리는 새로운 데이터에 대해 정확하게 예측하기를 바랍니다.
즉 훈련데이터에 너무 맞춰지면 과적합 현상이 발생합니다.
그러면 최적화된 C와 Gamma값을 어떻게 찾아낼 것인가? -> Grid Search
sklearn에 있는 Grid Search 알고리즘이 최적점을 찾아줍니다.
우리는 사용만 하면 되죠 ㅎㅎ.
# 방사형 기저 함수를 사용하고 그리드를 지정해 준다.
param_grid = {'C': [0.1, 1, 10, 100], 'gamma': [1, 0.1, 0.01, 0.001], 'kernel': ['rbf']}
# GridSearch알고리즘으로 학습시킨다.
from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(SVC(), param_grid, refit = True, verbose=4)
grid.fit(x_train_scaled, y_train)
#최적화 된 파라미터를 보여준다.
grid.best_params_
#예측값을 받는다.
grid_predictions = grid.predict(x_test_scaled)
#전과 같이 heatmap으로 직관적으로 보이게 만든다.
cm = confusion_matrix(y_test, grid_predictions)
sns.heatmap(cm, annot = True)코드는 이렇습니다!
C는 0.1부터 100까지 10배씩 키웠고
gamma값은 1에서 0.001까지 0.1배씩 줄였습니다.
총 16가지의 경우의 수가 생기겠네요!
이 중에서 가장 적합한 파라미터를 찾아줍니다.
(참고로 방사형 기저함수라는 것을 사용한다 정도로 알고 넘어가시면 됩니다.)
최적화 된 파라미터 값을 출력해 봤습니다.
{'C': 1, 'gamma': 1, 'kernel': 'rbf'}C는 1, Gamma는 1로 설정되어 있네요.
직관적으로 보기 위해 heatmap을 그려보면,
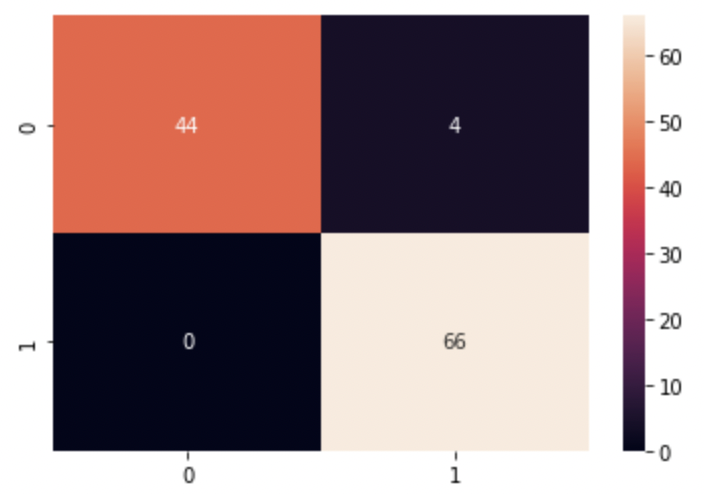
저번시간에 학습했던 것보다 좀 더 정확한 예측을 합니다.
지금까지 유방암 분류에 대한 실습을 해봤습니다!
다음시간에는 다른 주제로 실습내용을 가져오겠습니다.
( udemy강의를 통해 공부한 내용을 적었습니다.)
수고하셨습니다!
'Artificial Intelligence > Machine Learning 실습' 카테고리의 다른 글
| 주피터노트북 커널 죽음, The kernel appears to have died. It will restart automatically, 무조건 해결가능한 방법 (2) | 2023.01.16 |
|---|---|
| BREAST CANCER CLASSIFICATION(실습)-2 (1) | 2022.12.28 |
| BREAST CANCER CLASSIFICATION(실습)-1 (2) | 2022.12.27 |



댓글